DeepSeek缝合Claude,比单用R1/o1效果都好!GitHub揽星3k
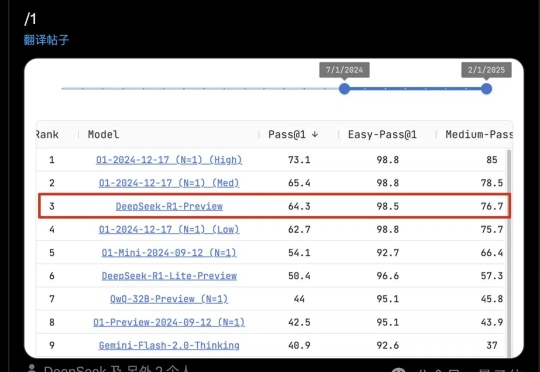
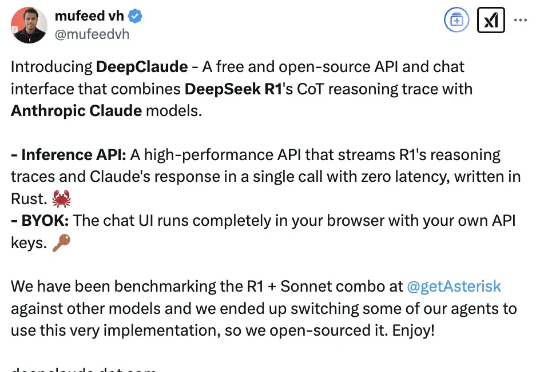
DeepSeek缝合Claude,比单用R1/o1效果都好!GitHub揽星3k让DeepSeek代替Claude思考,缝合怪玩法火了。原因无它:比单独使用DeepSeek R1、Claude Sonnet 3.5、OpenAI o1模型的效果更好。DeepClaude应用本身100%免费且开源,在GitHub上已揽获3k星星(当然API要用自己的)。
来自主题: AI资讯
11251 点击 2025-02-14 14:44